Table of contents
Related articles
EventManagement - Octopus Module
Introduction
Event Management is a process included in the ITIL® Service Operation phase:

By definition, an event is a "change of state that has significance for the management of an IT service or other configuration item (CI)". Events are typically recognized through alerts or notifications detected by a monitoring tool.
These detections of significant status change, the meaning given to them and the appropriate control measures that are performed are the major activities that are part of the Event Management process.
Event Management is the basis for the monitoring and control of IT operations.
Advantages
- Provides mechanisms for early detection of incidents. In many cases, it is possible for the event to be detected and assigned as an incident to the appropriate group for action before any actual service outage occurs;
- Automated detection takes into consideration significant alerts or notifications, thus removing the need for expensive and resource-intensive real-time monitoring, while reducing downtime;
- Reporting an event to a group that responds quickly improves the availability and allows system capacity tracking.
Principles and basic concepts
Event Types
There are 3 event types:
| Information |
Type of event that requires no action. Typically used to confirm the status of an equipment or a service, the success of a transaction or activity, or to generage statistical analysis. Examples:
|
| Warning |
Type of event signaling the approach of a threshold. Indicate that the situation should be checked and the appropriate actions taken to avoid an exception (failure). Example:
The warning means an unusual activity. It is an indication that the situation calls for increased surveillance. In some cases, it might resolve itself, for example, when an unusual increase workload occurs, once completed, the situation returns to a normal state. |
| Exception |
Type of event indicating that an equipment functions abnormally which causes or may cause a negative impact on business activities. Examples:
|
Each organization must define its rules for each event type, to ensure that the automatic mechanisms of monitoring systems are properly managed. Keep in mind that the "Information" events report data to use in decision making, the "Warning" events provide information about exceptions that may occur and the level of intervention to implement and "Exception" events indicate an abnormal situation for which an action must be taken.
Each type is based on messages sent and received, which are designated as event notifications that occur based on pre-established rules.
Process Diagram
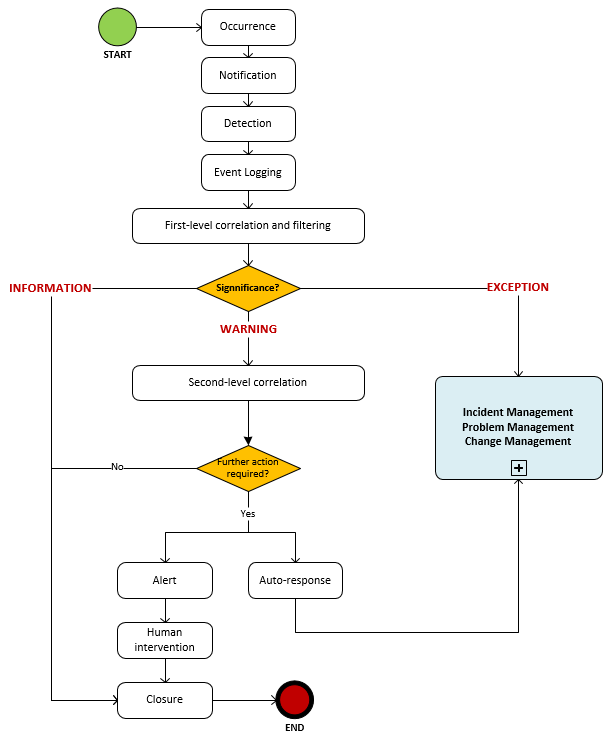
Activities
Occurrence: Among all the events that occur, which ones should be detected must be determined.
Notification: Issued by a CI or by a monitoring tool. There are 2 types:
- active tools, that query CIs on their status and availability;
- passive tools, that detect CI alerts and communications and make correlations to identify exceptions.
Detection: Once the notification is received, it is interpreted by the monitoring system or another management tool (such as Octopus).
Event Logging: Creation of the event request type in the request management tool.
First-level of correlation and filtering: According to the rules established in the correlation engine, the event is communicated to the management request system or it is ignored (filtering), and is identified as an event type:
- Information: no action
- Warning: an equipement reaches a threshold that requires a verification and potentially an automatic or manual action to prevent an exception (failure).
- Exception: a service or an equipment functions abnormally; business is impacted. The exception event will be transmitted as an incident, a problem or a change.
Second-level of correlation: If the event is a "Warning" type, a decision must be made about its significance and the appropriate actions to be taken. Correlation is enssured by a "correlation engine" (which is usually part of a management tool) which compares the event with a set of criteria in a prescribed order. These criteria are called "business rules". The idea is to design a system that identifies events that impact the business and use the rules to determine the level and type of impact.
By example:
- Number of similar events
- Number of CI generating similar events
- Specific action associated to a code or data
- Comparison of data usage according to a maximum or a minimum
- Other
If no action is required, the event will be logged for future reference.
Alert / Human Intervention: If the "Warning" event requires immediate attention, a notification is sent to the group responsible of the affected configuration item.
Auto-Response: Just as an "Exception" event, correlation rules of the management system can automatically create an incident, problem or change, and the new request will be managed through the corresponding processes.
Closure: Closing of "Information" or "Warning" event. The "Exception" event will be closed through the incident, problem or change processes.
Structure and rules
An organization must define and design exactly what, in the infrastructure and IT services, should be monitored and how it should be controlled. This structure must consider all of the decisions to be taken and the mechanisms to be put in place to execute these decisions.
- How event will be generated?
- How will they be classified?
- How will they be communicated?
- What data will be transmitted into the event request?
- Where events will be logged?
- Which level of automation must be applied?
Thank you, your message has been sent.